Поисковые системы
Поисковые системы (ПС) уже давно являются обязательной частью интернета и нашей повседневной жизни. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.

Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
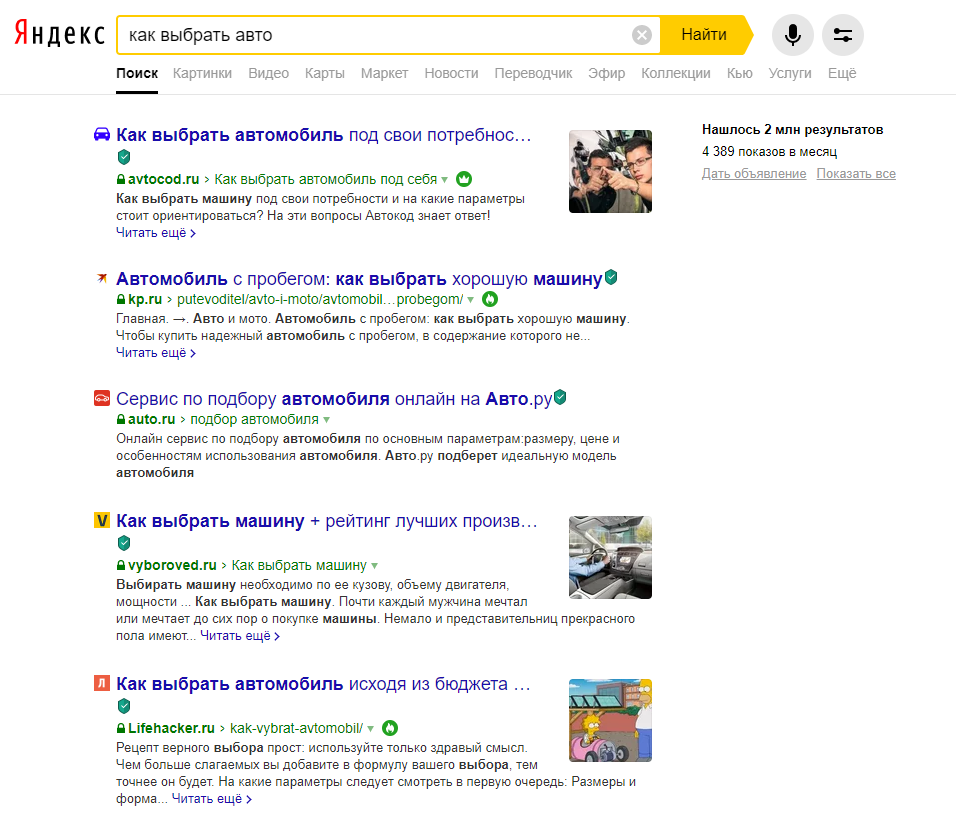
Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Туле»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. Приучить же пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?
Основные характеристики поисковых систем
Полнота.
Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.
Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.
К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.
Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самым известным и большим каталогом в мире был DMOZ (прекратил работу 14 марта 2017 года) имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.
Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.

В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.

В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.

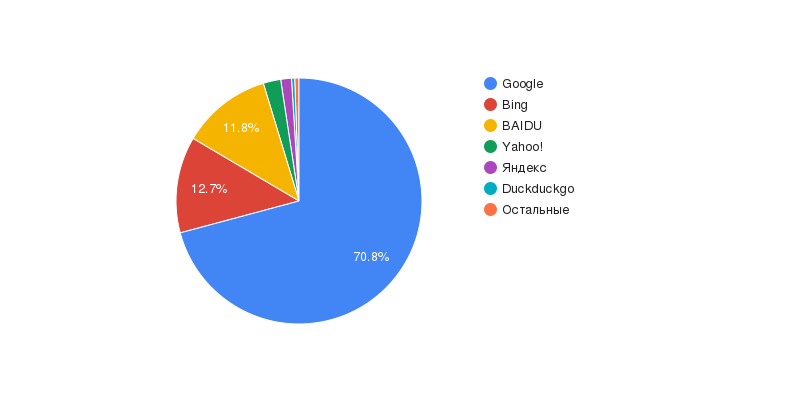
Доля поисковых систем
- Google — 70,83 %;
- Bing — 12,61 %;
- Baidu — 11,83 %;
- Yahoo! — 2,30 %;
- Яндекс — 1,41 %;
- DuckDuckGo — 0,42 %;

Принципы работы поисковой системы
Модуль индексирования.
Данный компонент состоит из трех программ-роботов:
Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.
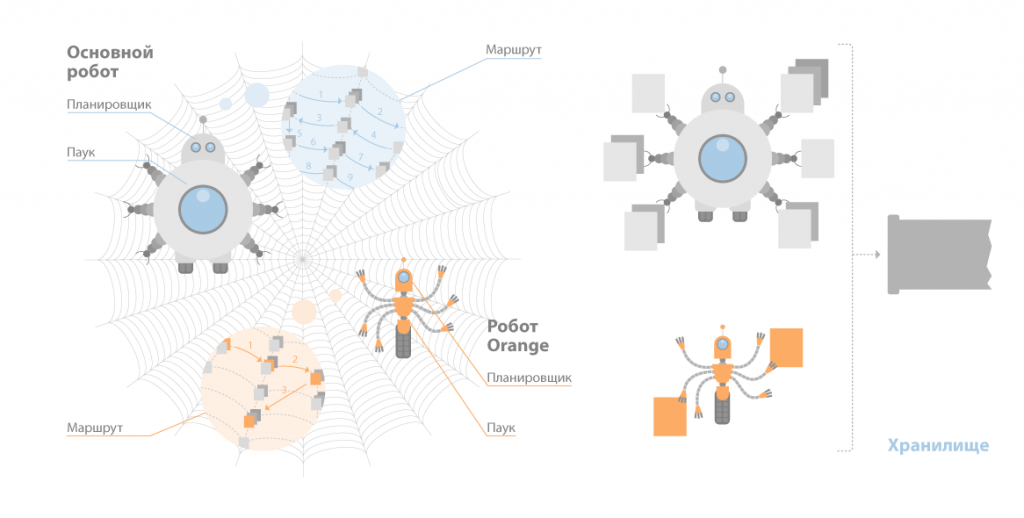
«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
Извлекаются все ссылки из тэгов. Вместе с ними обрабатывают редиректы. Любая скачанная страница сохраняется в таком формате:
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Crawler («путешествующий» паук). Данная программа автоматически заходит на все ссылки, которые найдены на странице, а также выделяет их. Его задача – определиться, куда в дальнейшем должен заходить паук, основываясь на этих ссылках или исходя из заданного списка адресов.
Crawler, исследуя найденные ссылки, ищет новые документы, еще не ставшие известными поисковой системе.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.
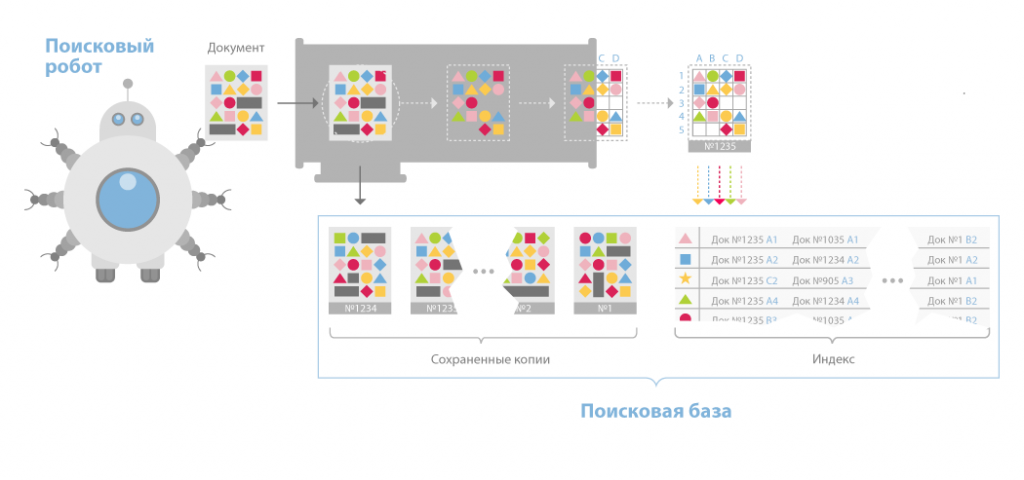
Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.
Поисковый сервер работает следующим образом:
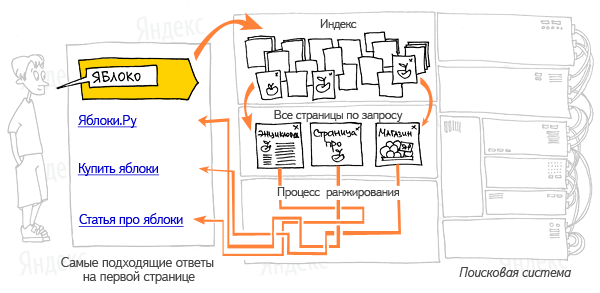
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Все эти элементы тесно связаны между собой и функционируют, взаимодействуя, образовывая отчетливый, но достаточно непростой механизм функционирования ПС, требующий громадных затрат ресурсов.
Поисковые машины и каталоги




![]()
![]()
Лабораторная работа №10.
Поиск информации в сети Internet
Цель работы
Познакомиться с основными поисковыми системами сети Интернет. Овладеть навыками работами в поисковых системах. Научиться выбирать оптимальную поисковую систему с учетом специфики поставленных задач.
Приборы и материалы
Для выполнения лабораторной работы необходим персональный компьютер, функционирующий под управлением операционной системы семейства WINDOWS. Должна быть установлена программа Internet Explorer.
Современные поисковые системы
Интернет — гигантское хранилище информации. Множество страниц, ценных и не очень, существуют безо всякого порядка и связанны между собой только случайными ссылками, зависящими от квалификации и личных пристрастий авторов сайтов. Однако пользователю необходимо ориентироваться в этом многообразии и находить, желательно за минуты, необходимую информацию.
В Интернет существует большое количество поисковых систем. По самым скромным оценкам, их более восьми тысяч, считая классические поисковые машины, общие и специализированные каталоги, а также метапоисковые Web-узлы (которые посылают запросы сразу на несколько поисковых серверов). В дополнение к этому существует ряд альтернативных средств поиска, способных вам пригодиться, включая утилиты, которые, работая совместно с браузером, добывают информацию из Web, и так называемые «экспертные узлы», где с вашими запросами работают живые люди. В настоящее время разрабатываются интеллектуальные поисковые системы. Примером такой системы может служить, например, интеллектуальная поисковая система Nigma(www.nigma.ru).
Поисковые машины и каталоги
При всем изобилии методов поиска в Internet наиболее распространенными средствами нахождения информации по-прежнему остаются поисковые машины и каталоги. Каждый из этих инструментов имеет определенные преимущества, а основная разница между ними заключается в участии/неучастии человека.
Поисковые машины – это комплекс специальных программ для поиска в сети.
Основные части программного комплекса:
1. Робот spider (паук). Автономно работающая программа, которая перебирает страницы сайтов, стоящих в очереди на индексацию. Она скачивает на диск поискового сервера содержимое исследуемых страниц.
2. Робот crawler (“путешествующий” паук). Его задача — собирать все ссылки на исследуемой странице, находить среди них новые, неизвестные поисковой системе, и добавлять их в список ожидающих индексации.
3. Индексатор. Обрабатывает страницы из очереди на индексацию. Для этого он составляет “словарь” странички, запоминает “частоту” использования слов. Особо отмечает ключевые слова, используемые в заголовках, выделенные в тексте жирным шрифтом. Помещает все это в особый файл — “индекс”.
4. База данных. Хранит ссылки на страницы, словарь встречаемых на странице слов и много другой информации, которая необходима для формирования результатов поиска.
5. Система обработки запросов и выдачи результатов.Принимает запрос пользователя, формирует запрос к базе данных, получает оттуда результат и передает его пользователю.
Поисковые машины запускают в Web программных «пауков», которые путешествуют со страницы на страницу и на каждой индексируют ее полный текст.
Практически у всех поисковых машин одинаковая форма запроса и примерно одинаковый формат выдачи результатов (см. пункт «Внешний вид поисковых страниц»), однако работа поисковых машин существенно различается. Во-первых, релевантностью (степенью соответствия результатов поиска запросу пользователя), во-вторых, величиной и частотой обновления баз данных, в-третьих, скоростью выдачи результатов. Ну и, конечно, поисковые машины различаются удобством работы.
На сегодняшний день поисковые системы — самые популярные страницы сети, на которых пользователи проводят очень много времени. Поэтому, все большее значение при выборе поисковика приобретают сопутствующие сервисы (почта, новостные ленты, торговые площадки и т.п.).

Каталоги— традиционное средство организации информации. Наверное, всем нам приходилось встречаться с библиотечными каталогами, каталогами товаров. Каталоги используются во множестве систем. Практически везде, где необходимо хранить и организовывать информацию.
Одна из основных задач, с которой сталкиваются составители каталогов — создать естественную, интуитивно понятную рядовому пользователю рубрикацию. К сожалению, данную задачу можно решить только с той или иной степенью приближения. Мир непрерывен, строгих границ в нем не существует. Один и тот же сайт можно рассматривать под разными углами зрения и видеть разные его функции. Каталоги формируются людьми-редакторами, которые прочитывают страницы, отсеивают неподходящие и классифицируют узлы по темам.
К недостаткам каталогов можно отнести следующее.
Во-первых, неоднозначность структуры — это явный минус каталожной организации информации (хотя он и несколько сглаживается тем, что в каждом крупном каталоге реализован поиск по каталогу).
Во-вторых, каталоги делают люди. Их полнота и качество зависят от количества и квалификации людей, занятых работой в каталоге, их личных вкусов и пристрастий. Неровность наполнения рубрик — характерная черта всех каталогов.
В- третьих, трудоемкость ручной рубрикации ограничивает объем каталогизируемой информации.
В тоже время безусловными достоинствами каталогов является то, что информация в нем хранится упорядоченно, в соответствии с элементарной человеческой логикой и релевантность найденных страниц при поиске в каталоге обычно на порядок выше, чем при поиске поисковыми системами.
Как было сказано выше, из-за того, что каталоги создаются вручную, они охватывают намного меньше ресурсов, чем поисковые машины. В Web сейчас, по самым скромным оценкам, насчитывается миллиард страниц (причем их число ежедневно увеличивается на миллион). Большинство поисковых машин не подошли сколько-нибудь близко к тому, чтобы проиндексировать всю Сеть. Исключением является Google (для России www.google.ru), который претендует именно на эту цифру — миллиард страниц, частично или полностью охваченных его индексами. Самый большой каталог — Open Directory Project (www.dmoz.org) — на этом фоне кажется крошечным: в него занесено лишь около 2 млн. страниц.
В 1994 г., когда начинался бурный рост «Всемирной паутины», выбор средств поиска в Сети был весьма ограниченным: Yahoo (www.yahoo.com). Этот сервер и по сей день остается краеугольным камнем исследования Web, но как каталог он столкнулся сейчас с жесткой конкуренцией со стороны Open Directory Project.
Многие каталоги весьма полезны, но с учетом всех обстоятельств предпочтение стоит отдать Open Directory Project. Проект Open Directory Project, инициированный компанией Netscape, реализуется усилиями редакторов-добровольцев со всего мира, которых насчитывается более 24 тысяч и которые проиндексировали около 2 млн. узлов b расклассифицировали их по более чем 200 тыс. категорий. Любой поисковый сервер может получить лицензию Open Directory Project и использовать его базу данных при обработке запросов, и на многих это сделано: AltaVista (www.altavista.com), HotBot (www.hotbot.com), Lycos (www.lycos.co.uk) и около сотни других серверов ныряют туда за ссылками.
Можно было бы ожидать, что, коль скоро каталог Open Directory Project создается силами добровольцев, качество результатов будет колебаться. Но в результате мы получаем хорошо организованные списки относящихся к теме страниц с четкими описаниями каждой ссылки. А узел Open Directory Project производит такое же впечатление, как Google: это «чистый поиск» без отвлекающих моментов типа ссылок на магазины.
Какой каталог ни выбрать, у всех есть одно преимущество перед поисковыми машинами: их можно систематически просматривать, пользуясь иерархической системой меню.







